
(Disclaimer: For those who have not seen this blog before, I must again point out that the views expressed here are those of the demonic Devil’s Neuroscientist, not those of the poor hapless Sam Schwarzkopf whose body I am possessing. We may occasionally agree on some things but we disagree on many more. So if you disagree with me feel free to discuss with me on this blog but please leave him alone)
In my previous post I discussed the proposal that all¹ research studies should be preregistered. This is perhaps one of the most tumultuous ideas that are being pushed as a remedy for what ails modern science. There are of course others, such as the push for “open science”, that is, demands for free access to all publications, transparent post-publication review, and sharing of all data collected for experiments. This debate has even become entangled with age-old faith wars about statistical schools of thought. Some of these ideas (like preregistration or whether reviews should be anonymous) remain controversial and polarizing, while others (like open access to studies) are so contagious that they have become almost universally accepted up to the point that disagreeing with such well-meaning notions makes you feel like you have the plague. On this blog I will probably discuss each of these ideas at some point. However, today I want to talk about a more general point that I find ultimately more important because this entire debate is just a symptom of a larger misconception:
Science is not sick. It never has been. Science is how we can reveal the secrets of the universe. It is a slow, iterative, arduous process. It makes mistakes but it is self-correcting. That doesn’t mean that the mistakes don’t sometimes stick around for centuries. Sometimes it takes new technologies, discoveries, or theories (all of which are of course themselves part of science) to make progress. Fundamental laws of nature will perhaps keep us from ever discovering certain things, say, what happens when you approach the speed of light, leaving them for theoretical consideration only. But however severe the errors, provided our species doesn’t become extinct through cataclysmic cosmic events or self-inflicted destruction, science has the potential to correct them.
Also science never proves anything. You may read in the popular media about how scientists “discovered” this or that, how they’ve shown certain things, or how certain things we believe turn out to be untrue. But this is just common parlance for describing what scientists actually do: they formulate hypotheses, try to test them by experiments, interpret their observations, and use them to come up with better hypotheses. Actually, and quite relevant to the discussion about preregistration, this process frequently doesn’t start with the formulation of hypotheses but with making chance observations. So a more succinct description of a scientist’s work is this: we observe the world and try to explain it.
Science as model fitting
In essence, science is just a model-fitting algorithm. It starts with noisy, seemingly chaotic observations (the black dots in the figures below) and it attempts to come up with a model that can explain how these observations came about (the solid curves). A good model can then make predictions as to how future observations will turn out. The numbers above the three panels in this figure indicates the goodness-of-fit, that is, how good an explanation the model is for the observed data. Numbers closer to 1 denote better model fits.

It should be immediately clear that the model in the right panel is a much better description of the relationship between data points on the two axes than the other panels. However, it is also a lot more complex. In many ways, the simple lines in the left or middle panel are much better models because they will allow us to make predictions that are far more likely to be accurate. In contrast, for the model in the right panel, we can’t even say what the curve will look like if we move beyond 30 on the horizontal axis.
One of the key principles in the scientific method is the principle of parsimony, also often called Occam’s Razor. It basically states that whenever you have several possible explanations for something, the simplest one is probably correct (it doesn’t really say it that way but that’s the folk version and it serves us just fine here). Of course we should weigh the simplicity of an explanation against it’s explanatory or predictive power. The goodness-of-fit of the middle panel is better than that of the left panel, although not by much. Nevertheless, it isn’t that much more complex than the simple linear relationship shown in the left panel. So we could perhaps accept the middle panel as our best explanation – for now.
The truth though is that we can never be sure what the true underlying explanation is. We can only collect more data and see how well our currently favored models do in predicting them. Sooner or later we will find that one of the models is just doing better than all the others. In the figure below the models fitted to the previous observations are shown as red curves while the black dots are new observations. It should have become quite obvious that the complex model in the right panel is a poor explanation for the data. The goodness-of-fit on these new observations for this model is now much poorer than for the other two. This is because this complex model was actually overfitting the data. It tried to come up with the best possible explanation for every observation instead of weighing explanatory power against simplicity. This is probably kind of what is going on in the heads of conspiracy theorists. It is the attempt to make sense of a chaotic world without taking a step back to think whether there might not be simpler explanations and whether our theory can make testable predictions. However, as extreme as this case may look, scientists are not immune from making such errors either. Scientists are after all human.
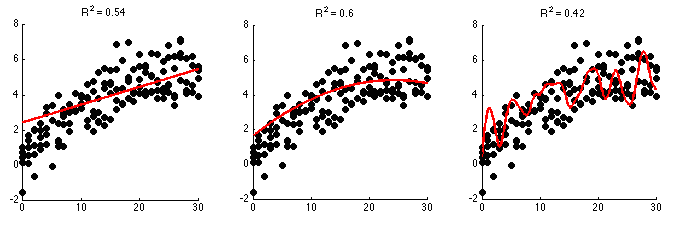
I will end the model fitting analogy here. Suffice it to say that with sufficient data it should become clear that the curve in the middle panel is the best-fitting of the three options. However, it is actually also wrong. Not only is the function used to model the data not the one that was actually used to generate the observations, but the model also cannot really predict the noise, the random variability spoiling our otherwise beautiful predictions. Even in the best-fitting case the noise prevents us from predicting future observations perfectly. The ideal model would not only need to describe the relationship between data points on the horizontal and vertical axes but it would have to be able to predict that random fluctuation added on top of it. This is unfeasible and presumably impossible without a perfect knowledge of the state of everything in the universe from the nanoscopic to the astronomical scale. If we tried this it will most likely look like the overfitted example in the right panels. Therefore this unexplainable variance will always remain in any scientific finding.

A scientist will keep swimming to find what lies beyond that horizon
Science is always wrong
This analogy highlights why the fear of incorrect conclusions and false positives that has germinated in recent scientific discourse is irrational and misguided. I may have many crises but reproducibility isn’t one of them. Science is always wrong. It is doomed to always chase a deeper truth without any hope of ever reaching it. This may sound bleak but it truly isn’t. Being wrong is inherent to the process. This is what makes science exciting. These ventures into the unknown drives most scientists, which is why many of us actually like the thought of getting up in the morning and going to work, why we stay late in the evening trying solve problems instead of doing something more immediately meaningful, and why we put up with pitifully low salaries compared to our former classmates who ended up getting “real jobs”. It is also the same daring and curiosity that drove our ancestors to invent tools, discover fire, and to cross unforgiving oceans in tiny boats made out of tree trunks. Science is an example of the highest endeavors the human spirit is capable of (it is not the only one but this topic is outside the scope of this blog). If I wanted unwavering certainty that I know the truth of the world, I’d have become a religious leader, not a scientist.
Now one of the self-declared healers of our “ailing” science will doubtless interject that nobody disagrees with me on this, that I am just being philosophical, or playing with semantics. Shouldn’t we guarantee, or so they will argue, that research findings are as accurate and true as they can possibly be? Surely, the fact that many primary studies, in particular those in high profile journals, are notoriously underpowered is cause for concern? Isn’t publication bias, the fact that mostly significant findings are published while null findings are not, the biggest problem for the scientific community? It basically means that we can’t trust a body of evidence because even in the best-case scenario the strength of evidence is probably inflated.
The Devil’s Neuroscientist may be evil and stubborn but she² isn’t entirely ignorant. I am not denying that some of the issues are problematic. But fortunately the scientific method already comes with a natural resistance, if not a perfect immunity, against these issues: skepticism and replication. Scientists use them all the time. For those people who have not quite managed to wrap their heads around the fact that I am not my alter ego, Sam Schwarzkopf, will say that I am sounding like a broken record³. While Sam and my humble self don’t see eye to eye on everything we probably agree on these points as he has repeatedly written about this in recent months. So as a servant of the devil, perhaps I sound like a demonic Beatles record: noitacilper dna msicitpeks.
There are a lot of myths about replication and reproducibility and I will write an in-depth post about that at a future point. Briefly though let me stress that, evil as I may be, I believe that replication is a corner stone of scientific research. Replication is the most trustworthy test for any scientific claim. If a result is irreplicable, perhaps because the experiment was just a once-in-an-age opportunity, because it would be too expensive to do twice, or for whatever other reason, then it may be interesting but it is barely more than an anecdote. At the very least we should expect pretty compelling evidence for any claims made about it.
Luckily, for most scientific discoveries this is not the case. We have the liberty and the resources to repeat experiments, with or without systematic changes, to understand the factors that govern them. We should and can replicate our own findings. We can and should replicate other people’s findings. The more we do of this the better. This doesn’t mean we need to go on a big replication rampage like the “Many Labs” projects. Not that I have anything against this sort of thing if people want to spend their time in this way. I think for a lot of results this is probably a waste of time and resources. Rather I believe we should encourage a natural climate of replication and I think it already exists although it can be enhanced. But as I said, I will specifically discuss replication in a future post so I will leave this here.
Instead let me focus on the other defense we have at our disposal. Skepticism is our best weapon against fluke results. You should never take anything you read in a scientific study at face value. If there is one thing every scientist should learn it is this. In writing scientific results look more convincing and “cleaner” than they are when you’re in the middle of experiments and data analysis. And even for those (rare?) studies with striking data, insurmountable statistics, and the most compelling intellectual arguments you should always ask “Could there be any other explanation for this?” and “What hypothesis does this finding actually disprove?” The latter question underlines a crucial point. While I said that science never proves anything, it does disprove things all the time. This is what we should be doing more of and we should probably start with our own work. Certainly, if a hypothesis isn’t falsifiable it is pretty meaningless to science. Perhaps a more realistic approach was advocated by Platt in his essay “Strong Inference“. Instead of testing whether one hypothesis is true we should pit two or more competing hypotheses against each other. In psychology and neuroscience research this is actually not always easy to do. Yet in my mind it is precisely the approach that some of the best studies in our field take. Doing this immunizes you from the infectiousness of dogmatic thinking because you no longer feel the need to prove your little pet theory and you don’t run control experiments simply to rule out trivial alternatives. But admittedly this is often very difficult because typically one of the hypotheses is probably more exciting…
The point is, we should foster a climate of where replication and skepticism are commonplace. We need to teach self-critical thinking and reward it. We should encourage adversarial collaborative replication efforts and the use of multiple hypotheses wherever possible. Above all we need to make people understand that criticism in science is not a bad thing but essential. Perhaps part of this involves training some basic people skills. It should be possible to display healthy, constructive skepticism without being rude and aggressive. Most people have stories to tell of offensive and irritating colleagues and science feuds. However, at least in my alter ego’s experience, most scientific disagreements are actually polite and constructive. Of course there are always exceptions: reviewer 2 we should probably just shoot into outer space.
What we should not do is listen to some delusional proposals about how to evaluate individual researchers, or even larger communities, by the replicability and other assessments of the truthiness of their results. Scientists must accept that we are ourselves mostly wrong about everything. Sometimes the biggest impact, in as far as that can be quantified, is not made by the person who finds the “truest” finding but by whoever lays the groundwork for future researchers. Even a completely erroneous theory can give some bright mind the inspiration for a better one. And even the brightest minds go down the garden path sometimes. Johannes Kepler searched for a beautiful geometry of the motion of celestial bodies that simply doesn’t exist. That doesn’t make it worthless as his work was instrumental for future researchers. Isaac Newton wasted years of his life dabbling in alchemy. And even on the things he got “right”, describing the laws governing motion and gravity, he was also really kind of wrong because his laws only describe a special case. Does anyone truly believe that these guys didn’t make fundamental contributions to science regardless of what they may have erred on?

May all your pilot experiments soar over the clouds like this, not crash and burn in misery
Improbability theory
Before I will leave you all in peace (until the next post anyway), I want to make some remarks about some of the more concrete warnings about the state of research in our field. A lot of words are oozing out of the orifices in certain corners about the epidemic of underpowered studies and the associated spread of false positives in the scientific literature. Some people put real effort into applying statistical procedures to whole hosts of published results to reveal the existence of publication bias or “questionable research practices”. The logic behind these tests is that the aggregated power over a series of experiments makes it very improbable that statistically significant effects could be found in all of them. Apparently, this test flags up an overwhelming proportion of studies in some journals as questionable.
I fail to see the point of this. First of all, what good will come from naming and shaming studies/researchers who apparently engaged in some dubious data massaging, especially when, as we are often told, these problems are wide-spread? One major assertion that is then typically made is that the researchers ran more experiments than they reported in the publication but that they chose to withhold the non-significant results. While I have no doubt that this does in fact happen occasionally, I believe it is actually pretty rare. Perhaps it is because Sam, whose experiences I share, works in neuroimaging where it would be pretty damn expensive (both in terms of money and time investment) to run lots of experiments and only publishing the significant or interesting ones. Then again, he certainly has heard of published fMRI studies where a whopping number of subjects were excluded for no good reason. So some of that probably does exist. However, he was also trained by his mentors to believe that all properly executed science should be published and this is the philosophy by which he is trying to conduct his own research. So unless he is somehow rare in this or behavioral/social psychology research (about which claims of publication bias are made most often) are for some reason much worse than other fields, I don’t think unreported experiments are an enormous problem.
What instead might cause “publication bias” is the tinkering that people sometimes do in order to optimize their experiments and/or maximize the effects they want to measure. This process is typically referred to as “piloting” (not sure why really – what does this have to do with flying a plane?). It is again highly relevant to our previous discussion or preregistration. This is perhaps the point where preregistration of an experimental protocol might have its use: First do lots of tinker-explore-piloting to optimize the ways to address an experimental question. Then preregister this optimized protocol to do a real study to answer the question but strictly follow the protocol. Of course, as I have argued last time, instead you could just publish the tinkered experiments and then you or someone else can try to replicate using the previously published protocol. If you want to preregister those efforts, be my guest. I am just not convinced it is necessary or even particularly helpful.
Thus part of the natural scientific process will inevitably lead to what appears like publication bias. I think this is still pretty rare in neuroimaging studies at least. Another nugget of wisdom about imaging Sam has learned from his teachers, and which is he is trying to impart on his own students, is that in neuroimaging you can’t just constantly fiddle with your experimental paradigm. If you do so you will not only run out of money pretty quickly but also end up with lots of useless data that cannot be combined in any meaningful way. Again, I am sure some of these things happen (maybe some people are just really unscrupulous about combining data that really don’t belong together) but I doubt that this is extremely common.
So perhaps the most likely inflation of effect sizes in a lot of research stems from questionable research practices often called “p-hacking”, for example trying different forms of outlier removal or different analysis pipelines and only reporting the one producing the most significant results. As I discussed previously, preregistration aims to control for this by forcing people to be upfront about which procedures they planned to use all along. However, a simpler alternative is to ask authors to demonstrate the robustness of their findings across a reasonable range of procedural options. This achieves the same thing without requiring the large structural change of implementing a preregistration system.
However, while I believe some of the claims about inflated effect sizes in the literature are most likely true, I think there is a more nefarious problem with the statistical approach to inferring such biases. It lies in its very nature, namely that it is based on statistics. Statistical tests are about probabilities. They don’t constitute proof. Just like science at large, statistics never prove anything, except perhaps for the rare situations where something is either impossible or certain – which typically renders statistical tests redundant.
There are also some fundamental errors in the rationale behind some of these procedures. To make an inference about the power of an experiment based on the strength of the observed result is to incorrectly assign a probability to an event after it has occurred. The probability of an observed event occurring is 1 – it is completely irrelevant how unlikely it was a priori. Proponents of this approach try to weasel out of this conundrum by stating that they assume the true effect size to be of a similar magnitude as what was observed in the published experiment and using this as the assumed power of the experiment. This assumption is untenable because the true effect size is almost certainly not that which was observed. There is a lot more to be said about this state of affairs but I won’t go into this because others have already summarized many of the arguments about this much better than I could.
In general I simply wonder how good statistical procedures actually are at estimating true underlying effects in practice. Simulations are no doubt necessary to evaluate a statistical method because we can work with known ground truths. However, they can only ever be approximations to real situations encountered in experimental research. While the statistical procedures for publication bias probably seem to make sense in simulations, their true experimental validity actually remains completely untested. In essence, they are just bad science because they aim to show an effect without a control condition, which is really quite ironic. The very least I would expect to see from these efforts is some proof that these methods actually work for real data. Say we set up a series of 10 experiments for an effect we can be fairly confident actually exists, for example the Stroop effect or the fact visual search performance for a feature singleton is independent of set size while searching for a conjunction of features is not. Will all or most of these 10 experiments come out significant? And if so, will the “excess significance test” detect publication bias?
Whatever the outcome of such experiments on these tests, one thing I already know: any procedure that claims to find evidence that over four of five published studies should not be believed is not to be believed. While we can’t really draw firm conclusions from this, the fact that this rate is the same in two different applications of this procedure certainly seems suspicious to me. Either it is not working as advertised or it is detecting something trivial we should already know. In any case, it is completely superfluous.
I also want to question a more fundamental problem with this line of thinking. Most of these procedures and demonstrations of how horribly underpowered scientific research is seems to make a very sweeping assumption: that all scientists are generally stupid. Researchers are not automatons that blindly stab in the dark in the hope that they will find a “significant” effect. Usually scientists conduct research to test some hypothesis that is more or less reasonable. Even the most exploratory wild goose chases (and I have certainly heard of some) will make sense at some level. Thus the carefully concocted arguments about the terrible false discovery rates in research probably vastly underestimate the probability of that hypothesized effects actually exist and there is after all “reason to think that half the tests we do in the long run will have genuine effects.”
Naturally, it is hard to put concrete numbers on this. For some avenues of research it will no doubt be lower. Perhaps for many hypotheses tested by high-impact studies the probability may be fairly low, reflecting the high risk and surprise factor of these results. For drug trials the 10% figure may be close to the truth. For certain effects, such as those precognition or telepathy or homeopathy, I agree with Sam Schwarzkopf, Alex Holcombe, and David Colquoun (to name but a few) that the probability that they exist is extremely low. But my guess is that in many fields the probability ought to be better than a coin toss that hypothesized effects exist.

To cure science the Devil’s Neuroscientist prescribes a generous dose of this potion (produced at farms like this one in New Zealand)
Healthier science
I feel I have sufficiently argued that science isn’t actually sick so I don’t think we need to wreck our heads about possible means to cure it. However, this doesn’t imply we can’t do better. We can certainly aim to keep science healthy or make it even healthier.
So what is to be done? As I have already argued, I believe the most important step we should take is to encourage replication and a polite but critical scrutiny of scientific claims. I also believe that at the root of most of the purported problems with science these days is the way we evaluate impact and how grants are allocated. Few people would say that the number of high impact publications on a resume tells us very much about how good a scientist a person is. Does anyone? I’m sure nobody truly believes that the number of downloads or views or media reports a study receives tells us anything about its contribution to science.
And yet I think we shouldn’t only value those scientists who conduct dry, incremental research. I don’t know what is a good measure of a researcher’s contribution on their field. Citations are not perfect but they are probably a good place to start. There probably is no good way other than hearsay and personal experience to really know how careful and skilled a particular scientist is in their work.
What I do know is that the replicability of one’s research and the correctness of one’s hypotheses alone aren’t a good measure. The most influential scientists can also be the ones who make some fundamental errors. And there are some brilliant scientists, whose knowledge is far greater than mine (or Sam’s) will ever be and whose meticulousness and attention-to-detail would put most of us to shame – but they can and do still have theories that will turn out to be incorrect.
If we follow down that dead end the Crusaders for True Science have laid out for us, if we trust only preregistered studies and put those who are fortuitous (or risk averse) enough to only do research that ends up being replicated on pedestals, in short, if we only regard “truth” in science, we will emphasize the wrong thing. Then science will really be sick and frail and it will die a slow, agonizing death.
¹ Proponents of preregistration keep reminding us that “nobody” suggests that preregistration should be mandatory or that it should be for all studies. These people I want to ask, what do you think will happen if preregistration becomes commonplace? How would you regard non-registered studies? What kinds of studies should not be preregistered?
² The Devil’s Neuroscientist recently discovered she is a woman but unlike other extra-dimensional entities the Devil’s Neuroscientist is not “whatever it wants to be.”
³ Does anyone still know what a record is? Or perhaps in this day and age they know again?

Many are forgetting one of the most powerful areas of science, mathematics. Mathematics, unlike other fields like physics or biology, strives to prove notions with absolute certainty. Surely, there is can be no “fudge factor” in a proof. But ignoring the mathematics part, I do agree with your post
LikeLike
I would hold mathematics as a separate discipline from science. That distinction may not always be appropriate but for the most part I think they are quite different. Math and logic can prove statements. Science can not.
LikeLiked by 1 person
Ahh…. True, if all your data goes into the mill and generates one answer that is adjusted by a fudge factor, then of course, you are right.
But… all this data in so many dimensions. Why do all these geniuses give us just one curve to fit? If the modeler really knows what they are talking about… why not a system of equations? We are used to underdetermined models. What rubbish. Why not overdetermined models. When you solve the same issue in multiple dimensions, then you can speak with confidence.
… and you might ask where does this happen? Check Joanne Kelleher’s stable isotope modelling of lipid biosynthesis for a breath of fresh scientific air.
LikeLike
Interesting comment. The reason for why we typically seek simply models is that science strives to reduce complexity. A completely unexplained world appears infinitely complex, unpredictable, and essentially chaotic. If our aim is to understand the world and make useful, accurate predictions for the future, you need to find the best-but-simplest model you can come up with. A “system of equations” is just a more complex (algorithmic) model. This may very well be appropriate in some contexts but only as long as nobody finds a simpler model that does just as well (or even almost as well).
Of course, there is way o the improve the model fit that I didn’t discuss in the post: you can reduce the noise. A lot of scientific effort is also spent on doing this. If I had reduced the noise level in this example the best fit might have been a lot more obvious as would have been the fact that none of the three curves describe the ground truth.
Anyway, I’m not a statistician. The model fitting example is an allegory for scientific investigation and that’s how we should discuss it. Science seeks the most appropriate explanation for observations weighing complexity against predictive power.
LikeLike
I love it, and my students will love this!
LikeLiked by 1 person
makes me think about research as fiction…maybe that’s all it is…congrats on being freshly pressed.
LikeLike
Agreed. Science, while it is very consuming and interesting, only ever proves that there is more to discover. Currently I am reading Love and Math by Frankel as well as Thinking in Numbers and am beginning to lean towards the avenues of mathematics to solve issues and prove things in tangible actuality.
LikeLike
Today’s research is tomorrow’s funding proposal.
LikeLiked by 1 person
Human knowledge is tend to be revised. Nothing is final
LikeLike
I’m sorry I have to disagree with “… that the replicability of one’s research and the correctness of one’s hypotheses alone aren’t a good measure.”
Instead, replicability and the best level of correctness are the foundation of education, and without further generations (who all have to learn and practice) there is no science at all.
LikeLiked by 2 people
The best way to achieve those results is to deal only with trivia.
LikeLike
I have no idea in what way your statement contradicts the sentence you quote from my post. Anyways, I don’t feel like elaborating on this point again as my posts tend to be verbose enough already. I clearly argued that replication is a corner stone of scientific progress. I merely said that whether or not effects replicate and turn out to be correct (which no science ever truly is anyway) is not in and of itself a great measure of good scientists. Good science is a measure of good scientists.
Anyway, I will talk about replication in my next post. I can now feel myself weakening as Sam wants his body for Christmas. I only managed to break through because he’s had no coffee yet today…
LikeLiked by 1 person
I have no idea what I just read.
LikeLiked by 1 person
Reblogged this on Tallbloke's Talkshop and commented:
.
.
An aeronautics expert writes sense about science. At the edge of design and testing in this field, the only thing between you and the field is thin, sharp-cold air.
Some disciplines force you to consider more precautionary principles than you could shake a climatologist at. But test pilots are adventurous and live life to the full. They push the edge hard in to see how it pushes back
LikeLike
How can I follow this blog? Loved the argument set forth.
LikeLike
I believe if you have a WordPress account there should be a link for following at the top. If not, I would just check back regularly. But I can explore if there are ways to make it simpler.
LikeLike
Sam, you seem unaware of your own RSS feeds. Your blog has one for new posts and one for new comments. In addition, each article has its own feed for comments on that article.
There are also email notification options. If a reader posts a comment to an article, they are presented with check boxes to be notified of new comments to the article and/or new posts.
LikeLiked by 1 person
https://devilsneuroscientist.wordpress.com/feed
LikeLike
Hmm. Writing under an alter ego that distances and exonerates you and making that alter ego a different gender to seal the differentiation is a curious psychological gambit.
LikeLike
Ever heard of Stephen Colbert? If yes, then maybe you can figure it out for yourself. If no, well, you never will again *sobs*
Anyway, the Devil’s Neuroscientist is well under control for the Christmas holidays and New Years celebrations. She will no doubt be back in January though. She’s hard to shake.
LikeLiked by 1 person
Oh, I think there’s muuuuch more to it than that but I’ve moved on to more interesting things.
Agreed, R.I.P. Colbert Report.
LikeLike
Not sure what much else there could be to it but please feel free to make speculations about mind (or that of my evil twin sister). I am actually unsurprised to get a comment like this – in fact I am more surprised that it took so long. But think about it this way: DNS could have just launched a blog anonymously? Would that be better?
Anyway, do come back in 2015. I’m sure DNS will be back at her desk happy to provide you with all the ‘interesting things’ you may wish for…
LikeLike
I have no problem with your alter-ego of a different gender paradigm. It seems quite reasonable to do so for the purpose here.
* Stephen Colbert is odious and annoying. You are not at all like that!
LikeLike
Reblogged this on Hire Marketer – Your Business Marketing Solution.
LikeLike
You say
“Thus the carefully concocted arguments about the terrible false discovery rates in research probably vastly underestimate the probability of that hypothesized effects actually exist and there is after all “reason to think that half the tests we do in the long run will have genuine effects.”
I can’t agree with that. The thing that persuaded me to take the false discovery rate seriously was the realisation that deciding on a prior is NOT necessary for the conclusion that P=0.047 implies that you have AT LEAST a 30% chance of having made a false discovery. There are at least two ways that this can be shown. See http://rsos.royalsocietypublishing.org/content/1/3/140216
or the version of the same thing on arXiv http://arxiv.org/abs/1407.5296
Simply doing simulated t tests is sufficient to show that the minimum false discovery rate is around 26% if you use P = 0.05 as a cut off, quite regardless of the prior probability of their being a real effect. It’s true that this gets still worse when the prior is small, but 26% is the minimum.
LikeLike
This statement seems to directly contradict what you wrote in your paper in that the false discovery rate will be substantially lower (and closer to alpha level) if there is a 50% chance that a hypothesized effect exists.
Rather with 80% power and 50% true effects the FDR should be just shy of 6%. With 30% power, which the Crusaders tell us is much more common in our field, it should be around 14%. I agree that’s higher than nominal levels but nowhere near as bad as what you suggest. And this is based on the 50% notion which, as I argued in my post, is probably incorrect in many fields. I do agree though that with drug tests your 10% rate is perhaps appropriate. You’d know this better than me.
LikeLike
Uhuh, the numbers that you quote are from the initial tree diagram approach. That’s an easy way to introduce the problem, but you have to penetrate a bit further into the paper to see why it’s not a sufficient solution to the problem. If you read sections 5 – 11, I think you’ll find that the minimum false discovery rate (for P = 0.05) is indeed 26% regardless of the prior.
LikeLike
I think what your exposition is really showing is that we should use statistical approaches that focus on evidence rather than on a dichotomous decision criterion. That could be Bayesian hypothesis testing or it could simply be based on precision (confidence intervals) or anything really not based on a uniform distribution.
LikeLike
In any case, I can’t confirm this assertion (that prior has no effect) when simulating or even theoretically. If the prior is 100% you will have no false discovery rate. That’s obviously nonsense but my point was that the prior is likely higher than 50%. With 67% the FDR is 14%? I am presumably missing something very essential about your argument.
Either way, as I said in my last comment, I think an evidence-based procedure is the better call than simply moving to a more conservative significance threshold.
LikeLike
Yes, I think you are missing something. There is a sense in which a prior of 50% is the best case and that still gives an FDR for simulated t tests or 29% for the Berger approach. Of course if you increase the prior still more the FDR falls, simply because almost all tests will have a real effect. Neither of these approaches assumes anything about the prior, In fact for reasons that I explain, I don’t think that there is any need to describe them as Bayesian. They are merely an application of the laws of conditional probability to perfectly objective probabilities.
You say “I think what your exposition is really showing is that we should use statistical approaches that focus on evidence rather than on a dichotomous decision criterion.”
I certainly don’t think that dichotomous decision making is a good idea (though it’s exactly what permeates much of the literature). That’s why I conclude that one should “never ever use the word ‘significant’ ”
But the first half of your sentence begs the question of what should be used. What should you use as evidence? Confidence intervals are fine, but they tell you nothing whatsoever about the false discovery rate,
It seems to me to be indisputable that false discoveries are a problem and that they are what we should be concentrating on. Ignoring this problem must, I think, be quite a large contribution to the fact that most published papers are wrong (Ioannidis is like a breath of fresh air).
I have to agree with the physicist/journalist Robert Matthews when he said:
“The plain fact is that 70 years ago Ronald Fisher gave scientists a mathematical machine for turning baloney into breakthroughs, and flukes into funding. It is time to pull the plug”.
Aren’t you trying to brush a real problem under the carpet?
LikeLike
Exactly. It was precisely my point that in many contexts the prior should be even larger.
Of course, I’m not saying that false positives don’t exist. Of course they do. I don’t even mind promoting ways to reduce this. I think evidence quantification can be via Bayes Factors or you can make inferences about the reliability of your results from confidence intervals. I don’t think you need to worry about false discovery rates if you do this in a principled way.
Anyways, my main argument is that science is always wrong. This includes the situations in which your finding is not a false positive. To be fair, I think you may have a point when talking about the clinical or drug-testing context. In that situation you are interested in finding something that works even if you aren’t really sure how it works. False positives can be highly damaging. Just as with preregistration, I think clinical or pharmacological studies require different strategies than basic science.
LikeLike
Wow! I love your implication that pharmacology is not basic science. Try this http://www.onemol.org.uk/c-hatton-hawkes-03.pdf
More seriously, I fear that your assertion that the prevalence of true effects (prior, if you must) is 50% or even higher, is pure hubris. I’d be astonished if it were that high. And it wouldn’t make matters much better even if you were right about that. In sections 9 – 11 of http://rsos.royalsocietypublishing.org/content/1/3/140216 it’s shown that there would still be a false discovery rate of 26%.
It’s no wonder that there is a crisis of reproducibility!
LikeLike
Okay, I accept the comment about pharmacology may have been poorly phrased. It was late and my alter ego wanted his body back…
Anyway, I’ve run simulations of my own and I included Bayesian hypothesis tests (http://pcl.missouri.edu/bf-two-sample) in this. The false discovery rate shown at the top of each of these graphs is the one you would calculate for 0.045<p<=0.05. The false discovery rates plotted on the y-axis is the one you would get if you picked a Bayes factor (BF10 quantifying evidence for the alternative hypothesis) or log(x)<log(BF10)<log(x)+0.1. Obviously you shouldn't be doing that but lets imagine (probably rightly so) that most researchers stick to their dichotomous thinking, in which case this gives a good indication.
Unless the proportion of real effects is very low the FDR under this Bayesian scheme would be very modest. It is admittedly still fairly high for the 10% case (albeit much less than under classical statistics): https://www.dropbox.com/s/v9opnv04n721gab/10%25.png?dl=0
For 50% it is low: https://www.dropbox.com/s/aaa74cjrp9grch8/50%25.png?dl=0
For 70%, which I think is actually likely in most basic science contexts, it is negligible: https://www.dropbox.com/s/fptys0yu1fyjmk3/70%25.png?dl=0
(Note on the figures, the red lines indicate common evidence criteria for the alternative hypothesis. The dotted line is where we pass beyond anecdotal evidence (BF10=3) and the dashed line is BF=10 beyond which I would evidence as conclusive enough to be taken seriously).
I think the problem is that we can't easily put numbers on what the true proportion of real effects is. Posthoc probabilities as are typically used for evaluating the statistical power in the literature are not an adequate way to do this. The point I made in my post is that a large number of hypotheses tested by scientists are in fact likely to be somewhat true. First of all, the true null hypothesis is generally wrong – there will always be trivial differences which you end up detecting with classical statistics with high powered experiments. Secondly, even if an hypothesis is a poor descriptor of the true underlying process, it can still be reasonably correct.
I agree with you, however, that this does not apply to drug testing and clinical trials. If we want to know if a treatment works (or works better than a conventional treatment), false discovery rates are certainly a bigger concern. This is why I believe preregistration is also very sensible for clinical trials. But for basic science (which doubtless includes a lot of pharmacology :P) this is not the case.
I thank you a lot for your comments but I don't wish to continue this much further (also, Sam wants his body back to finish the pre-Christmas workload…). The major point of my post is not to poke holes into your paper. I think that all makes sense and I don't have the same qualms with that one as I do with the Test of Excess Significant or other such procedures. I simply wanted to question two things: first, I don't believe false positives are as likely in many basic science contexts as you assert, and second, I think even if there are a lot of false positives this is not a problem. Basic science doesn't have to be right all of the time, maybe not even most of the time. However, when basic science turns into applied science our focus should shift and I agree with you that a firmer control of FDR is needed there.
LikeLike
Ah! Goethe (Johann Wolfgang von Goethe, by name): Men (before feminism) with their figures do contend their lofty systems to defend!
LikeLike
I would like to response to your comments about the test for excess significance/success (TES).
1) Applying the TES is not about naming/shaming researchers. It is about checking whether the presented theoretical conclusions are consistent with the reported data. If the degree of success in the data is inconsistent with the theoretical conclusions that are espoused by the authors, then it indicates that the original authors are not providing a sufficient argument for their theory.
2) Apparently biased experiment sets are not _proven_ to be biased, but they do appear to be biased. Such an appearance of bias does not mean that the theories are wrong or that effect does not exist, but it means that proponents of the theory or effect need to present a different argument to support their ideas. The burden of proof is on them.
3) It is a little odd that the TES investigations of Psychological Science and Science produced similar percentages of studies that appear biased (82 and 83 percent). But I think you are making too much of circumstance. The law of small numbers is not actually a valid law.
4) I find it strange that you ask for validation of the TES when we know the ground truth, but then dismiss simulation work that provides exactly that validation. You asked for some examples in “real situations”, and there have been cases that follow up on a TES analysis.
a) Wishful seeing (http://i-perception.perceptionweb.com/journal/I/article/i0519ic): The analysis finds Ptes=0.076. In a reply, the original authors admit that they had an additional non-significant experiment, but it was removed at the request of the reviewers. The authors replaced it with a significant experiment.
b) Aversive memory (http://pps.sagepub.com/content/7/6/585.full): The initial analysis finds Ptes=0.079 (some variations of the analysis make the number even lower). The authors reply (http://pps.sagepub.com/content/7/6/595.full) explained that they did have several non-significant findings.
c) Verbal overshadowing (http://link.springer.com/article/10.3758%2Fs13423-012-0227-9): From a meta-analysis of the verbal overshadowing effect, the TES analysis finds Ptes=0.022. A registered replication report (RRR2, http://pps.sagepub.com/content/9/5/556.full) found that the effect size (Cohen’s h) is about the same (h=-0.33) as the estimate from the original meta-analysis (h= -0.30). A difference between the earlier meta-analysis and the RRR is the proportion of significant outcomes. For the RRR, 8 out of 22 (36 percent) of the studies rejected the null. That is pretty close to what a TES analysis of the data suggests should happen (the sum of the estimated power values across the 22 experiments in the RRR is 7.9). In contrast, for the earlier meta-analysis, 9 out of 18 studies (50 percent) rejected the null. The sum of the estimated power values indicates that one would expect around 4.7 significant rejections.
d) Weight and importance (http://link.springer.com/article/10.3758/s13423-014-0601-x; Table 2 Jostmann et al.): The TES analysis finds Ptes=0.090. The original authors reported (http://rolfzwaan.blogspot.nl/2013/10/effects-are-public-property-and-not.html; Questions 8-9) that they had a non-significant result that they did not publish with the paper (they later posted it at the PsychFiledrawer site).
e) Red, rank, and romance (http://www.ncbi.nlm.nih.gov/pubmed/23398185): The TES analysis finds Ptes=0.005 (there are several variations of the analysis discussed in the paper, but they all indicate the appearance of bias). In a published response (http://www.ncbi.nlm.nih.gov/pubmed/23398186), the authors reported a replication experiment of their main effect. Although it had a much larger sample size than their original studies, it produced a much smaller effect size (Hedge’s g=0.25) than the estimate from the original studies (g=0.78). Moreover, the replication experiment was not statistically significant.
f) Consuming experience (https://pubpeer.com/publications/AEA8ACCF57E1E2527C0D8F59648D5F): The TES analysis finds Ptes=0.003. In their reply (same page), the authors note that they ran other studies on the effect and did not publish the non-significant findings.
Of course, we do not know the “ground truth” for any of the above findings, but you asked for some examples so here they are.
5) Your questions about the Stroop effect reflect misunderstandings about interpreting replications. You ask whether all or most of ten Stroop experiments will produce a significant outcome, but you are not providing enough information for anyone to give an answer. Even if the effect is real, not every experiment will produce a significant outcome (due to random sampling), and it is less likely for smaller sample sizes. Let’s say the Stroop effect has a Cohen’s d=1 (for a paired t-test). Then if you have 10 subjects in each experiment, you have a power of 0.8, and you would expect 8 out of 10 experiments to reject the null. All ten experiments would reject the null with a probability of 0.8^10 = 0.11.
If you have 20 subjects in each experiment, you have a power of 0.99. The probability that all ten such experiments would reject the null is 0.99^10 = 0.90.
If you have 5 subjects in each experiment, you have a power of 0.4. The probability of all ten such experiments rejecting the null is 0.4^10=0.0001. If someone reported such a success rate for these kinds of experiments, I would be very skeptical of their results.
6) I do not feel that a study failing the TES means we have to interpret the authors as being frauds or fools. Science is difficult, and I think it is much more difficult than most scientists realize. My guess is that the biggest problem is the overfitting process that you described in your post. Researchers may take almost any significant outcome as evidence for a theory and almost any non-significant outcome as establishing a limit/boundary to the theory. But such an approach leads to overfitting and poor generalization, which is what the TES demonstrates.
7) In most cases, using the estimated effect size to calculate estimated power makes the TES more conservative than if you knew the true effect size. You can see the simulations in my JMP article (http://www.sciencedirect.com/science/article/pii/S002224961300014X) that demonstrate this property (and also describes situations where it is more liberal).
8) I was rather surprised by Alex Etz’s comment (above) about the TES. In our conversation at his blog (http://nicebrain.wordpress.com/2014/12/06/should-we-buy-what-greg-francis-is-selling-nope/#comments) I thought we had concluded that his main concern with the TES was its use of frequentist-style reasoning, and that his other concerns were addressed in our conversation. I share some of Alex’s concerns about frequentist-style reasoning, but I think it can be done properly in some settings. Moreover, if one really feels the frequentist approach is fundamentally flawed, then you are already skeptical about most of the findings in psychology and you do not need the TES to convince you. At Alex’s blog there is an unfinished conversation between me and Richard Morey. I am waiting for him to present an example of what he describes as a fundamental flaw in the TES. His previous example was shown to not work.
LikeLike
Thanks for your comments about the TES. I don’t really mean to wade into the statistical debate about this as others have already said far more of that than I could. I just remain unconvinced of this approach because I think it is entirely untested. I appreciate your examples of cases where it revealed that there were some unpublished, non-significant experiments. However, without any knowledge of the ground truth this is pretty meaningless because we can neither tell the sensitivity nor the specificity of the test. The fact that 83ish per cent of studies are flagged up as dubious could just mean that it revealed these particular cases by chance.
Simulations are great (Sam uses them all the time) but they make assumptions that don’t always hold. Experimental evidence is still the best evidence. I believe there may actually be confounding factors that result in reduced effect sizes with increasing numbers of replications that are unrelated to inflated publication bias and false positives. Just compare a primary on trained psychophysical observers with one with three times the sample size but using randomers off the street. The effect size estimates may very well be different but they may nonetheless both be completely correct.
You’re right that I didn’t provide sufficient detail about the validation experiment I suggested. I think such experiments should be designed based on typical parameters in the literature. Don’t make any assumptions about power for the true effect size, even though with the Stroop effect you probably could. Modify each experiment in some way as you would in a real study where you investigate some actual research question. Perhaps add some dependencies between the experiments (such as partially overlapping samples) that I don’t believe you take into account in your TES analyses? Then tell me what this shows. Of course, to really make any informed decisions you would have to do that many times…
To be honest, I find the concept of statistical power moronic. We never know the true effect size and we definitely can’t make any reasonable assumptions about power after the fact. This all stems from the dichotomy of significance testing that treats science as a series of coin tosses. If there is one point on which I agree with the Crusaders, it is that we must abandon this dichotomizing. I do think though that this is harder said than done and I will discuss that in a future post about Statistical Faith Wars.
Anyway, as I said in the post, I just fail to see the point of all these TES analyses. What are you trying to prove exactly? I am actually quite willing to believe that many statistics are excessively significant. I don’t think the reasons for that are mostly omitted experiments because this simply doesn’t match my experience of how most labs work. I also don’t believe in the extremeness of questionable research practices, although I can believe that there are practices that skew effect sizes upwards. I am very happy about efforts to counteract that, such as the discussion about optional stopping. More importantly, I am very much in favor of changing the way publishing and grant allocation work so that they reduce the pressure to publish exciting significant results.
As for the TES not being about naming and shaming, I think you’re being naive here. It is the same bright-eyed gullibility displayed by the preregistration proponents when they say that it won’t be mandatory or that exploratory and confirmatory research will not be held to different standards. This is no doubt how it seems to them in their heads but it isn’t how things work in the real world. Your approach for using the TES is clearly “naming” researchers. As for “shaming” this is obviously more subjective. But by saying that the probability of bias is high you are making an accusation, explicit or not.
LikeLiked by 1 person
The point of the TES analysis is that some people take psychology studies and their resulting theories seriously. Somewhere there is a business school that is advising future CEOs that they will make better decisions for complex situations by following their gut rather than deliberating on the details (Ptes=0.051). A person seeking a job is using heavy weight paper to make his vitae seem more important (Ptes=0.017). Another company is painting their meeting rooms blue to improve creativity and their offices red to improve detail-oriented performance (Ptes=0.002). A dietician is advising clients to control their eating by simply imagining eating (Ptes=0.012). Schools are having their students write about their exam worries in order to boost test scores (Ptes=0.059). Charities are revising their approaches to dealing with poverty because scarcity leads to attentional shifts related to overborrowing (Ptes=0.091).
I don’t object to companies or individuals trying these approaches if they wish; but they should not be told that the science backs up these approaches. The field of psychology really does investigate important and useful topics. When we get it right or wrong there are consequences.
That’s the applications outside of science. Within science it may be even worse. Thousands of other researchers are exploring variations of these findings and theories. Oftentimes the grunt work falls on graduate students and post docs who end up dejected and rejected because they cannot reproduce “established” findings. Perhaps even worse, the students learn how to produce the same kind of biased results and thereby pass the problem on to the next generation and they largely waste their careers by studying biased effects. Let’s not even think about the wasted grant money on such projects.
Mind you, I am not saying that all of those effects or theories are necessarily or entirely wrong; but the burden of proof is on the proponents, and the presented articles do not make a good scientific argument. This, by the way, is rather different than your observation that science is always wrong. I think you meant that errors are inevitable and we need to recognize that no theory is perfect. That’s fine, but I am talking about a different kind of error. The theories described in these articles do not make sense given the data they present.
I know that shaming is part of the process, and I take no pleasure in it. But if we really care about our scientific results and theories, then we have a responsibility to identify mistakes. I do want CEOs to make better decisions, I do want job seekers to present themselves in a good way, I do want to improve creativity and detail-oriented performance, I do want people to eat less, I do want students to do better on exams, and I do want charities to deal appropriately with the poor. I believe that psychological science can make a positive contribution to those issues, but it has to do it in a scientific way. We cannot continue to pretend that these studies are valid just because we do not want to hurt our peers’ feelings. That just potentially passes the hurt on to someone else (who follows the advice given by these kinds of studies).
With maybe a couple of exceptions, I do not think many scientists are deliberately introducing bias into their work, but it can happen so easily! In the PLOS One paper, we tried to describe how what are sometimes labelled as questionable research practices are almost the same thing as standard operating procedure or, sometimes, as best practices. The “named” scientists did not want to produce biased findings, they just did not understand how to make a convincing scientific argument when the signal is small and the noise is big. I cannot say whether they should be “shamed”, but I think everyone wants to do better.
LikeLike
The point of the TES analysis is that some people take psychology studies and their resulting theories seriously.
Do you honestly believe TES analysis is going to change this? How many people who are not psychologists (I’m a ‘neuroscientist’, by the way…) will even know let alone have an opinion about the statistical issues here? I feel you need to get out of the science-community bubble.
I don’t want anyone to make business, hiring, advertising, or any other kinds of practical decisions based on bad scientific evidence. I am horrified by the thought that the Myers-Briggs personality test is used by HR departments. I am bemused by the crap that gets reported by the news media as things that “scientists have discovered.” Just this week Chris Chambers and Petroc Sumner (among many) published a paper about how science news are being distorted and that a lot of this miscommunication starts with the original scientists and the press releases put out by their institutions.
I entirely agree that this has to change. I vehemently disagree that the TES is the way to solve this problem. I don’t even think it addresses the actual problem. The real problem is that the way science is published, how it is reported, how grants are awarded, and who gets the jobs depends on things that have nothing to do with scientific scrutiny and critical thinking. This has to change.
I don’t have all the answers unfortunately. I am happy to hear suggestions how this system can be improved. But I am sure that pointing out the obvious, that there is wide-spread publication bias and inflated false positives, is not the way to achieve it.
LikeLike
I don’t know if the TES is going to change things, but I feel it is worth a try. I also support other efforts to produce change. I don’t expect non-scientists to think about these issues at all, but I do hope scientists will. I believe most scientists want to derive good theories from their data, but they do not know how to do it. If the topic is important, then information should (eventually) spread from scientists to the general public.
I think there are problems at multiple levels. I agree that scientific reporting, grant awarding, and hiring have serious problem. But we are not going to make much scientific progress, even if we fix all of those problems, if scientists still generate theories that are inconsistent with their data.
The people reading this blog are probably among the minority who already believe something is wrong. Most of our colleagues know that there is a fuss going on, but they do not follow it closely. (I am always surprised at how many psychologists have not even heard about the Bem precognition studies.) Using the TES to point out problems with current research is not the solution to the problems, it is a means of highlighting and characterizing important aspects of the problems.
As for solutions, I think there are basically two ways to go. Bayesian and cross-validation methods for model testing/comparison. The Bayesian approach is more principled (good) but cross-validation is sometimes easier to understand (good). I think there is room for both. This is not a widely held view. Most people think they can just do hypothesis testing properly, which I think is misguided and is only going to lead to further confusion. For example, I am not as enamoured about pre-registration as some reformers. I’m not opposed to it, but I think it is not really going to solve our problems (although not for the reasons you have given). I had a debate with Chris Chambers about it in the comments on Gelman’s blog: http://andrewgelman.com/2014/01/23/discussion-preregistration-research-studies/
LikeLike
Thanks for your comments about preregistration and the link to your discussion. I agree with some of your views I think. I certainly agree that methods that remove the emphasis on dichotomy (which could be Bayesian but don’t need to be) would be a good way forward. I also entirely agree about cross-validation being a good idea. This is also very much in line with the model-fitting example I gave in the blog post.
I haven’t met many people who hadn’t heard about Bem’s precognition experiments, but I have met a lot of people who don’t know what a Bayes Factor is and who haven’t heard about the notion of questionable research practices etc. I must say I do find that surprising.
LikeLike
“Lies, damned lies, and psychological science”
Psychological science can do no wrong ! Who cares about the fact the problem with low powered studies has been known for decades, who cares about the taxpayers money that is being wasted on more low-powered, p-hacked studies: don’t you know science is self-correcting ! Everything will turn out alright in the end, don’t you worry your pretty little head about a thing. We scientists know what to do, really! Lies…
If psychological science is so interested in “finding out the truth”, why are failed replications so viciously attacked as if there is something wrong with them, or with those that performed them? Doesn’t it lead to more knowledge about possible “boundary conditions”? Why aren’t researchers thrilled with the additional knowledge they possibly gained? Lies…
In the meantime we will just go ahead and not pre-register anything, because our possible false-positive will surely be replicated by someone, right ? I mean that’s what happens a lot in science you know: replication. It’s not like we all kind of trust everything we read, because we don’t really care about whether it is true or not. I mean we even talk about findings in the classroom, text-books, and in press-reports like they have some uncertainty in them. We totally do not describe these findings as facts, we really don’t ! We only care if we can use it as a reference for our own article, which of course only depicts very careful language which shows science’s uncertainty. It most definitely not uses bold, over-estimating claims. O no, not today’s science. Lies…
Science is such a great enterprise to work in: you can almost never do anything wrong. There is almost no accountability and almost no responsibility for anything. It’s a wonder they haven’t let Diederik Stapel back in the game. “science is always wrong”, “psychological science is such a young discipline still so,,,”, “don’t name any names, ever?!”, “why point out research that is probably p-hacked/ low-powered, we all know it is being done (hereby totally leaving out the important part of why this is being done: to show what research to trust and which not)”. Lies…
LikeLiked by 1 person
Lies? Seriously? You are attacking a straw man and if you went any further you’d set him on fire.
Science is self-correcting. It is inherent to the process itself. It is true that we can do it badly or we can do it well. By “badly” I mean preregistering everything and only regarding science that has been replicated by 200 labs as trustworthy and ignoring everything else. This way science will move at a snail’s pace and there won’t be any more real progress before the turn of the next millennium. Nobody will dare to do anything new or risky because if you find something it will be disproved sooner or later anyway, it will almost never happen with preregistered studies (at least not using the methods that have been preregistered), and nobody regards chance (“p-hacked”?) findings as useful. So the most well regarded scientists will be the ones who are content at publishing failed but beautifully preregistered replications. Actually eventually even that will cease because there will be nothing interesting left for these parasites to replicate.
By “doing it well” I mean letting scientist do what they do best. Dare to try something new. I don’t give a damn if it is “true”. I don’t even give a damn if it is “p-hacked” to be honest. Don’t mistake me for a straw man – I don’t think p-hacking is good thing and it should certainly be discouraged. But it can mean a lot of things and I don’t honestly believe that the really bad kind of p-hacking is as common as certain people would have as believe. It certainly is pretty unlikely to be true that 83% of published results are meaningless as the excess significance folks claim.
I won’t go into your assertions about replication because I want to write a full post about replication in the future that will address this point. Let me just say that, yes, scientists replicate results. The reason why failed replications receive such a hostile backlash is that people forget that replication attempts are science too. Science is always wrong, remember? This includes the replications.
The Crusaders for True Science like to put people failing to replicate newsworthy/sensational findings on a pedestal in their Temple of Scientific Perfection. It is idiotic. Both kinds of science should be held to the same standard but contrary to the common protestations this is not what these people actually do. They have a clear agenda – they just don’t want to admit it because it would reveal how unscientific they actually are.
I never said we shouldn’t change things. In fact I clearly advocated ways that could help improve matters. I just don’t believe the solution lies in idealism and increased regulation of the scientific process. I prefer to train scientists who are better at critical thinking and who are able to have skeptical yet constructive discussions. I want to see replications that can convince the original authors, not serve the public profile of the replicators. I want to see changes to the way grants are awarded that actually rewards good scientists which doesn’t mean the guys who are dull enough to only do 100% replicable research.
As for the tax payer, I am a tax payer too. My taxes are wasted by our government on a lot of things that I never approved of. Unnecessary research really isn’t a big problem in the big scheme. But even if it were, I would rather see my taxes to be used for a few “p-hacked” studies that turn out to be overstated, than to waste them on a many labs replication project that fails to replicate a result I never cared about to begin with.
LikeLiked by 1 person
I am sure you are probably familiar with the following articles, but I think they most clearly indicate anything useful I could possibly add:
1) False-positive psychology: undisclosed flexibility in data collection and analysis allows presenting anything as significant
http://www.ncbi.nlm.nih.gov/pubmed/22006061
2) Measuring the prevalence of questionable research practices with incentives for truth telling
Click to access MeasPrevalQuestTruthTelling.pdf
3) Why most research findings are false
http://www.plosmedicine.org/article/info%3Adoi%2F10.1371%2Fjournal.pmed.0020124
4) Why science is not necessarily self-correcting
http://pps.sagepub.com/content/7/6/645.full.pdf+html
5) Scientific misconduct and the myth of self-correction in science
Click to access Perspectives%20on%20Psychological%20Science-2012-Stroebe-670-88.pdf
LikeLiked by 1 person
It is these kinds of crusading publications that inspired me to take over poor Sam’s mind and write these blog posts. I haven’t read all of these papers but I have read most of them (actually Sam has, but I share his memories). I will respond specifically about numbers 4-5 at some stage. Number 3 was obviously what inspired the title of my post…
LikeLiked by 1 person
I do think we have a serious problem on our hands, at least in some fields, and I think the current (dismal) results of the (preregistered) replication attempts attest to this. To answer your question about when do to preregistration: research that aims to test hypotheses needs to be of the hypothesis-testing type (i.e., purely confirmatory, hence prereg needed); research that aims to generate hypotheses is exploratory and does not need prereg. Violate this rule by testing hypotheses in a hypothesis-generating context and the stats become meaningless. Cheers, EJ (Wagenmakers)
LikeLiked by 1 person
Thanks for your response. I am genuinely interested in the answers to these questions.
I think you are overstating the evidence for the “dismal” results of preregistered replication attempts. I’m not talking about single studies. Preregistered or not, a single study doesn’t really tell us all that much more than no studies. The most interesting news I’ve heard about these many labs replication projects has been that they first failed to replicate until they realized that the (preregistered) protocol was inadequate. Ooops.
Anyway, if we’re reading between the lines I think what you are saying is that only purely exploratory work should not be preregistered. So in other words, you are basically advocating preregistration for all research because in all honesty there is very little purely exploratory research. Most good research is in fact a hybrid and it is better that way. You guys often point out that the point of prereg is to make the distinction between exploration and confirmation clearer. I don’t actually have a problem with that. I just think preregistration, while a naively obvious solution, isn’t the way to do it.
LikeLike
Hi Sam, interesting post. I agree with a lot of it, especially where you point out the oddities of the excess significance test. The fact that the two times it has been put to systematic use resulted in almost identical rates of “excess success” is a strange invariance that makes me wonder what it is really measuring (I’m tempted to answer: nothing). I am especially reluctant to believe that a simple test like this can tell us what value the research under investigation actually has. And my conversation with Francis in the comments didn’t strengthen my confidence in the method.
One thing you write that gives me pause is when you expressly dismiss the value of pre-registration. I think I can somewhat understand what you mean, but I’m wondering if you would elaborate so I can get a better idea. Your reply to EJ above is especially interesting. You state that research is (and should be) a combination of both exploration and confirmation. I agree with you in that regard. I am curious about the end of your comment. Are you saying you don’t have a problem with wanting to distinguish between exploration and confirmation, but that pre-registration wouldn’t work? Would you mind saying why you think that it wouldn’t work? “This study was pre-registered wrong” isn’t exactly a convincing argument, if you don’t mind me saying. Pre-registering a study is super easy and (when done correctly, of course :P) ensures the statistics being used retain their intended meaning.
Looking forward to hearing your thoughts on this, thanks for writing a thought-provoking post.
-Alex
LikeLiked by 1 person
Thanks for your comment. I don’t feel like elaborating enormously on the point of preregistration considering I have recently already written a long commentary about this. May I direct you to “The Pipedream of Preregistration” (http://wp.me/p5oZ1i-q)? I will be happy to discuss the points raised in that post further of course. In short though, I think it will not work. It will either never be adopted properly or, if it is adopted widely, it will stifle the progress of science and add a massive bureaucratic burden. It is also focusing on the wrong thing rather than encouraging replication and scrutiny of reported findings.
Also, my opinion isn’t Sam’s. I don’t really know where he stands on preregistration. I don’t think he knows either 😛
LikeLiked by 1 person
Thanks for pointing me towards your other post, I’ll check it out.
LikeLiked by 1 person